![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
This chapter includes:
When you're dealing with timing, every moment within the Neutrino microkernel is referred to as a tick. A tick is measured in milliseconds; its initial length is determined by the clock rate of your processor:
Programmatically you can change the clock period via the ClockPeriod() function.
The tick size becomes important just about every time you ask the kernel to do something relating to pausing or delaying your process. This includes calls to the following functions:
Normally, you use these functions assuming they'll do exactly what you say: “Sleep for 8 seconds!”, “Sleep for 1 minute!”, and so on. Unfortunately, you get into problems when you say “Sleep for 1 millisecond, ten thousand times!”
Does this code work assuming a 1 ms tick?
void OneSecondPause() {
/* Wait 1000 milliseconds. */
for ( i=0; i < 1000; i++ ) delay(1);
}
Unfortunately, no, this won't return after one second on IBM PC hardware. It'll likely wait for three seconds. In fact, when you call any function based on the nanosleep() or select() functions, with an argument of n milliseconds, it actually takes anywhere from n to infinity milliseconds. But more than likely, this example will take three seconds.
So why exactly does this function take three seconds?
What you're seeing is called timer quantization error. One aspect of this error is actually something that's so well understood and accepted that it's even documented in a standard: the POSIX Realtime Extension (1003.1b-1993/1003.1i-1995). This document says that it's all right to delay too much, but it isn't all right to delay too little — the premature firing of a timer is undesirable.
Since the calling of delay() is asynchronous with the running of the clock interrupt, the kernel has to add one clock tick to a relative delay to ensure the correct amount of time (consider what would happen if it didn't, and a one-tick delay was requested just before the clock interrupt went off).
![]()
A single 1 ms sleep with error.
That normally adds half a millisecond each time, but in the example given, you end up synchronized with the clock interrupt, so the full millisecond gets tacked on each time.
![]()
Twelve 1 ms sleeps with each one's error.
The small error on each sleep accumulates:
![]()
Twelve 1 ms sleeps with the accumulated error.
OK, that should make the loop last 2 seconds — where's the extra second coming from?
The problem is that when you request a 1 ms tick rate, the kernel may not be able to actually give it to you because of the frequency of the input clock to the timer hardware. In such cases, it chooses the closest number that's faster than what you requested. In terms of IBM PC hardware, requesting a 1 ms tick rate actually gets you 999,847 nanoseconds between each tick. With the requested delay, that gives us the following:
Since the kernel expires timers only at a clock interrupt, the timer expires after ceil(2.000153) ticks, so each delay(1) call actually waits:
999,847 ns * 3 = 2,999,541 ns
Multiply that by a 1000 for the loop count, and you get a total loop time of 2.999541 seconds.
So this code should work?
void OneSecondPause() {
/* Wait 1000 milliseconds. */
for ( i=0; i < 100; i++ ) delay(10);
}
It will certainly get you closer to the time you expect, with an accumulated error of only 1/10 of a second.
The hardware timer of the PC has another side effect when it comes to dealing with timers. The “Oversleeping: errors in delays” section above explains the behavior of the sleep-related functions. Timers are similarly affected by the design of the PC hardware.
For example, let's consider the following C code:
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/neutrino.h>
#include <sys/netmgr.h>
#include <sys/syspage.h>
int main( int argc, char *argv[] )
{
int pid;
int chid;
int pulse_id;
timer_t timer_id;
struct sigevent event;
struct itimerspec timer;
struct _clockperiod clkper;
struct _pulse pulse;
uint64_t last_cycles=-1;
uint64_t current_cycles;
float cpu_freq;
time_t start;
/* Get the CPU frequency in order to do precise time
calculations. */
cpu_freq = SYSPAGE_ENTRY( qtime )->cycles_per_sec;
/* Set our priority to the maximum, so we won't get disrupted
by anything other than interrupts. */
{
struct sched_param param;
int ret;
param.sched_priority = sched_get_priority_max( SCHED_RR );
ret = sched_setscheduler( 0, SCHED_RR, ¶m);
assert ( ret != -1 );
}
/* Create a channel to receive timer events on. */
chid = ChannelCreate( 0 );
assert ( chid != -1 );
/* Set up the timer and timer event. */
event.sigev_notify = SIGEV_PULSE;
event.sigev_coid = ConnectAttach ( ND_LOCAL_NODE,
0, chid, 0, 0 );
event.sigev_priority = getprio(0);
event.sigev_code = 1023;
event.sigev_value.sival_ptr = (void*)pulse_id;
assert ( event.sigev_coid != -1 );
if ( timer_create( CLOCK_REALTIME, &event, &timer_id ) == -1 )
{
perror ( "can't create timer" );
exit( EXIT_FAILURE );
}
/* Change the timer request to alter the behavior. */
#if 1
timer.it_value.tv_sec = 0;
timer.it_value.tv_nsec = 1000000;
timer.it_interval.tv_sec = 0;
timer.it_interval.tv_nsec = 1000000;
#else
timer.it_value.tv_sec = 0;
timer.it_value.tv_nsec = 999847;
timer.it_interval.tv_sec = 0;
timer.it_interval.tv_nsec = 999847;
#endif
/* Start the timer. */
if ( timer_settime( timer_id, 0, &timer, NULL ) == -1 )
{
perror("Can't start timer.\n");
exit( EXIT_FAILURE );
}
/* Set the tick to 1 ms. Otherwise if left to the default of
10 ms, it would take 65 seconds to demonstrate. */
clkper.nsec = 1000000;
clkper.fract = 0;
ClockPeriod ( CLOCK_REALTIME, &clkper, NULL, 0 ); // 1ms
/* Keep track of time. */
start = time(NULL);
for( ;; )
{
/* Wait for a pulse. */
pid = MsgReceivePulse ( chid, &pulse, sizeof( pulse ),
NULL );
/* Should put pulse validation here... */
current_cycles = ClockCycles();
/* Don't print the first iteration. */
if ( last_cycles != -1 )
{
float elapse = (current_cycles - last_cycles) /
cpu_freq;
/* Print a line if the request is 1.05 ms longer than
requested. */
if ( elapse > .00105 )
{
printf("A lapse of %f ms occurred at %d seconds\n",
elapse, time( NULL ) - start );
}
}
last_cycles = current_cycles;
}
}
The program checks to see if the time between two timer events is greater than 1.05 ms. Most people expect that given QNX Neutrino's great realtime behavior, such a condition will never occur, but it will, not because the kernel is misbehaving, but because of the limitation in the PC hardware. It's impossible for the OS to generate a timer event at exactly 1.0 ms; it will be .99847 ms. This has unexpected side effects.
As described earlier in this chapter, there's a 153-nanosecond (ns) discrepancy between the request and what the hardware can do. The kernel timer manager is invoked every .999847 ms. Every time a timer fires, the kernel checks to see if the timer is periodic and, if so, adds the number of nanoseconds to the expected timer expiring point, no matter what the current time is. This phenomenon is illustrated in the following diagram:
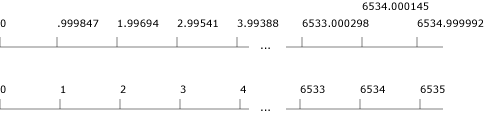
Actual and expected timer expirations.
The first line illustrates the actual time at which timer management occurs. The second line is the time at which the kernel expects the timer to be fired. Note what happens at 6534: the next value appears not to have incremented by 1 ms, thus the event 6535 won't be fired!
For signal frequencies, this phenomenon is called a beat. When two signals of various frequencies are “added,” a third frequency is generated. You can see this effect if you use your camcorder to record a TV image. Because a TV is updated at 60 Hz, and camcorders usually operate on a different frequency, at playback, you can often see a white line that scrolls in the TV image. The speed of that line is related to the difference in frequency between the camcorder and the TV.
In this case we have two frequencies, one at 1000 Hz, and the other at 1005.495 Hz. Thus, the beat frequency is 1.5 micro Hz, or one blip every 6535 milliseconds.
This behavior has the benefit of giving you the expected number of fired timers, on average. In the example above, after 1 minute, the program would have received 60000 fired timer events (1000 events /sec * 60 sec). If your design requires very precise timing, you have no other choice but to request a timer event of .999847 ms and not 1 ms. This can make the difference between a robot moving very smoothly or scratching your car.
There are several functions that you can use to determine the current time, for use in timestamps or for calculating execution times:
All the above methods have an accuracy based on the system timer tick. If you need more accuracy, you can use ClockCycles(). This function is implemented differently for each processor, so there are tradeoffs. The implementation tries to be as quick as possible, so it tries to use a CPU register if possible. Because of this, to get accurate times on SMP machines, you need to use thread affinity to lock the thread to a processor, because each processor can have a ClockCycles() base value that may not be synchronized with the values on other processors.
Some caveats for each processor:
To convert the cycle number to real time, use SYSPAGE_ENTRY(qtime)->cycles_per_sec.
 |
SH and MIPS are based on a 32-bit clock, so they can wrap around. You should use ClockCycles() only for short durations. |
If you need a pause, use delay() or the POSIX clock_nanosleep().
If you need a very short delay (e.g. for accessing hardware), you should look at the nanospin*() functions:
They basically do a while loop to a calibrated number of iterations to delay the proper amount of time. This wastes CPU, so you should use it only if necessary.
|
|
|
|